MySQL 编程规范
审核规范
- 数据库运维脚本, 向 DBA 审核开发权限。
- 表结构变更 DBA 审核未通过的,不允许上线。
- 运维 SQL 脚本必须本地执行成功才能提交合并,由 DBA 部署运维脚本。
基础规范
- 库名/表名/字段名统一小写。
- 库名/表名/字段名注释业务场景。
- 库名/表名/字段名禁止使用
mysql保留字。 - 库名/表名/字段名小写字母、见名知意、下划线命名。
- 数据对象/变量命名采用英文字符,禁止中文命名。
- 临时库/表名必须以
tmp为前缀,并以日期为后缀。 - 备份库/表必须以
bak为前缀,并以日期为后缀。 - 禁止明文存储密码。
- 禁止跨库访问数据。
表设计规范
基本概念
表类型:
- 实体表: 客观存在的事物数据,比如说员工。
- 事实表: 通过各种维度和指标值组合确定的一个事实,比如通过时间、地域组织维度,指标值可以确定在某时某地的一些指标值怎么样的事实。事实表的每一条数据都是几条维度表的数据和指标值交汇而得到的。
- 维度表: 对事实的各个方面描述,比如时间维度表;维度表只能是事实表的一个分析角度。
术语:
- 关系: 实体表之间的联系
- 元组: 表的一行
- 属性: 表的一列
- 键(码): 唯一标识元组的最小属性集
- 候选码: 二维表会存在多个键(码)统称为候选键(码), 从中选择一个作为用户使用的键称为主键
范式定义
- 第一范式:对属性的原子性约束,不可再分解;
- 第二范式:对**元组(记录)**的惟一性约束,即实体的惟一性;
- 第三范式:对字段冗余性的约束,即任何字段不能由其他字段派生出来。
- 巴斯-科德范式(BCNF): 每个表中只有一个候选键
- 第四范式: 消除表中的多值依赖。
注意:落地到第三范式就已够用了,后面的太严格,不符合实际使用。必要的空余(预计算列)可以提升查询效率(以空间换时间)。
E-R图规范
结构清晰、关联简洁、实体个数适中、属性分配合理、没有低级冗余。
注: 功能文档中会使用到 E-R 图,并约束上述规范。
完整性约束
- 域的完整性:用Check来实现约束
- 参照完整性:用PK、FK、表级触发器来实现。
- 用户定义完整性:是业务规则,用存储过程和触发器来实现。
三少原则
- 数据库中表的个数越少越好
- 表中组合主键的字段个数越少越好
- 表中的字段个数越少越好
数据库设计的实用原则是:在数据冗余和处理速度之间找到合适的平衡点。
“三少”是一个整体概念,综合观点,不能孤立某一个原则。该原则是相对的,不是绝对的。
提倡“三少”原则的目的,是防止利用打补丁技术,不断地对数据库进行增删改,使企业数据库变成了随意设计数据库表的“垃圾堆”,或数据库表的“大杂院”,最后造成数据库中的基本表、代码表、中间表、临时表杂乱无章,不计其数,导致企事业单位的信息系统无法维护而瘫痪。
通用原则
表名使用复数(后缀
s)。推荐
utf8mb4。utf8mb4是真正意义上的utf-8。必须有主键,使用
id自增列作主键;再创建uuid字段,作为业务主键。存储状态、性别等,用
tinyint(1),慎用enum。日期字段,类型使用
date,xxx_date命名。时间字段,类型使用
datetime,xxx_datetime命名。价格等小数类型使用
decimal(10, 2)。同一意义的字段设计定义必须相同(便于联表查询)
表与表之间需要建立关联关系时使用
uuid关联。禁止
default null,建议not null。表设计时基础字段
create table mysql_guides s(
`id` int(11) not null auto_increment,
`uuid` varchar(50) not null comment 'uuid',
...
`delete_status` tinyint(1) default 0 comment '删除状态, 0/1',
`created_time` datetime default current_timestamp comment '创建时间',
`updated_time` datetime default current_timestamp on update current_timestamp comment '更新时间',
primary key(id)
)
datetime & timestamp
索引设计
- 唯一索引命名
uniq_字段1_字段2,非唯一索引命名idx_字段1_字段2。 - 建立索引时,务必先
explain,查看索引使用情况;禁止冗余索引;禁止重复索引。 - 重要的 SQL 中
where条件里的字段必须被索引。 - 不在低基数列上建立索引,例如“性别”。
- 不要在频繁更新的列上建立索引。
- 不在索引列进行数学运算和函数运算(参与了运算的列不会引用索引)
- 复合索引须符合最左前缀的特点建立索引(MySQL 使用复合索引时从左向右匹配)
SQL 规范
建议 SQL 语句小写,包括 SQL 关键字、保留字。
selectfromleft joinright joininner joinwheregroup byorder bylimit左对齐右缩进为两个空格。
join与on在同一行。SQL 代码段之间空一行。
鼓励添加简洁的注释,增加代码阅读性。
单字段赋值, 必须
limit 1。use mysql;
-- 高版本 MySQL 约束强,没有显式 limit 1 直接抛语法错误
set @user = (
select `User`
from user
limit 1
);
select convert(@user using utf8) as user;多字段赋值, 使用一条
select。use mysql;
-- 本质是使用最后一行结果集赋值
-- 1. 若 limit 2,赋值的是第二行结果集
-- 2. `:=` 是赋值, `=` 是比较
select
@host := `Host`,
@user := `User`
from user
limit 1;
select
convert(@host using utf8) as host,
convert(@user using utf8) as user;或
use mysql;
select
`Host`, `User` into @host, @user
from user
limit 1;
select
convert(@host using utf8) as host,
convert(@user using utf8) as user;事务(
transaction)与 ACIDdrop procedure if exists `pro_sql_acid_example`;
delimiter ;;
create procedure `pro_sql_acid_example`()
begin
declare is_sql_error integer default 0;
declare continue handler for sqlexception set is_sql_error = 1;
start transaction;
-- 业务SQL, CRUD 语法错误时,取消本次所有数据操作
-- 业务SQL一切正常,此处返回结果集
if is_sql_error = 1 then
rollback;
select 'rollback with sql exception';
-- 根据业务需要,返回对应的内容
else
commit;
-- 此时仅 commit, 避免查询结果集语句出错
end if;
end
;;
delimiter ;
call pro_sql_acid_example();
查询规范
- 拆分复杂 SQL 为多个小 SQL,或创建汇总中间表(利用
query cache和多核cpu)。 - 用
in代替or。in的个数控制在 1000 以内。 - 不使用负向查询,如
not in/like。 - 用
union all代替union;union all不需要对结果集再进行排序。 - 禁止使用
order by rand()。 select、insert语句必须显式的指明字段名称。where条件中的非等值条件(in/between/</<=/>/>=)会导致后面的条件使用不了索引。- 使用合理的分页方式以提高分页(
limit)的效率。 - 减少与数据库交互次数,尽量采用批量sql语句。
- a)
insert on duplicate key update - b)
replace into(禁止使用) - c)
insert ignore - d)
insert into values()
- a)
存储过程
- 使用
pro_存储过程名。 - 接收参数使用
var_字段名。 - 接收参数将:
in var_data_enterprise_uuid varchar (100),in var_data_enterprise_code varchar (100)放置接收参数的末尾。 - 尽可能减少游标的使用。
业务场景
建表时必带字段:
`id` int(11) not null auto_increment,
`uuid` varchar(50) default null comment 'uuid',
`creater_uuid` varchar(50) default null comment '创建人uuid',
`created_time` datetime default current_timestamp comment '创建时间',
`updater_uuid` varchar(50) default null comment '更新人 uuid',
`updated_time` datetime default current_timestamp on update current_timestamp comment '更新时间',
`data_enterprise_uuid` varchar(100) default null comment '数据所属企业uuid',
`data_enterprise_code` varchar(100) default null comment '数据所属企业号',
`delete_status` varchar(100) default '0' comment '删除状态, 0 未删除 1 已删除',建表时必带索引:
unique key `index_uuid` (`data_enterprise_uuid`,`uuid`)uuid类型统一为varchar(50)。如数量等字段需要设置默认值。
尽可能减少主数据字段的变动,如有特定需求建立主数据关联表进行连接。
当表与表之间需要建立关联关系时尽量使用
uuid关联。
命名规范
- 模糊查询统一使用字段
fuzzy_search命名。 - 表名称命名第一段使用统一项目名称命名。
- 当a表与b表为一对多的关系,b表为a表的明细内容时,表名称命名为:
a表名_detail(a表明细表)。 - 当需要接受当前登录人的
uuid时,使用emp_uuid字段接收。 - 当需要接受分页时,使用
start_num、end_num字段接收。
SQL 规范
查询时
join表时如无特殊情况需加上data_enterprise_code和delete_status的关联筛选。编写 SQL 时
where条件中养成带上data_enterprise_data、data_enterprise_code和delete_status字段的筛选。传递给前端的参数使用驼峰形式别名。
count统一使用count(*)。列表页查询传递筛选时使用以下规范:
and case
when '#筛选字段名#' = 'all' or '#筛选字段名#' = '' then
1 = 1
else
数据库字段名 like '%#筛选字段名#%'
end列表默认使用
order by updated_time desc。
应用场景规范
REP标题命名规范:
1.查询 - 获取xxx列表
2.查询 - 获取xxx详情
3.查询 - 获取xxx明细列表
4.查询 - 统计xxx数量
5.查询 - xxx校验
6.修改 - 修改xxx
7.新增 - 新增xxx需访问数据库的表单校验尽量使用多个接口实现校验。
如需要查询加上增(删改)时,选择
*/select权重类型。当需要使用
if判定等操作时使用存储过程完成。当需要接受对象数组进行操作时走固定接口完成。
尽量保持一个项目一个分组。
所有接口需经过 PostMan 测试通过才算完成。
所有接口按模块使用印象笔记呈现,基本格式规范如下:
标题:接口文档-xxx模块
正文:
### 新增(修改、删除) - 新增(修改、删除)xxx
#### 请求参数
{
repcode:'rep_0000xx',
repgroup:'xxx',
请求参数1字段名:'', // 请求参数1
请求参数1字段名:'', // 请求参数2
}
### 查询 - xxxxx
#### 请求参数
{
repcode:'rep_0000xx',
repgroup:'xxx',
请求参数1字段名:'默认值', // 请求参数1
}
#### 接收参数
{
接收参数1字段名:'', // 接收参数1
}
功能文档
详情内链: 职场协作-功能文档
梳理建表语句,确认字段都有备注
梳理说明业务 SQL 并补充注释
整理业务表模型 E-R 图
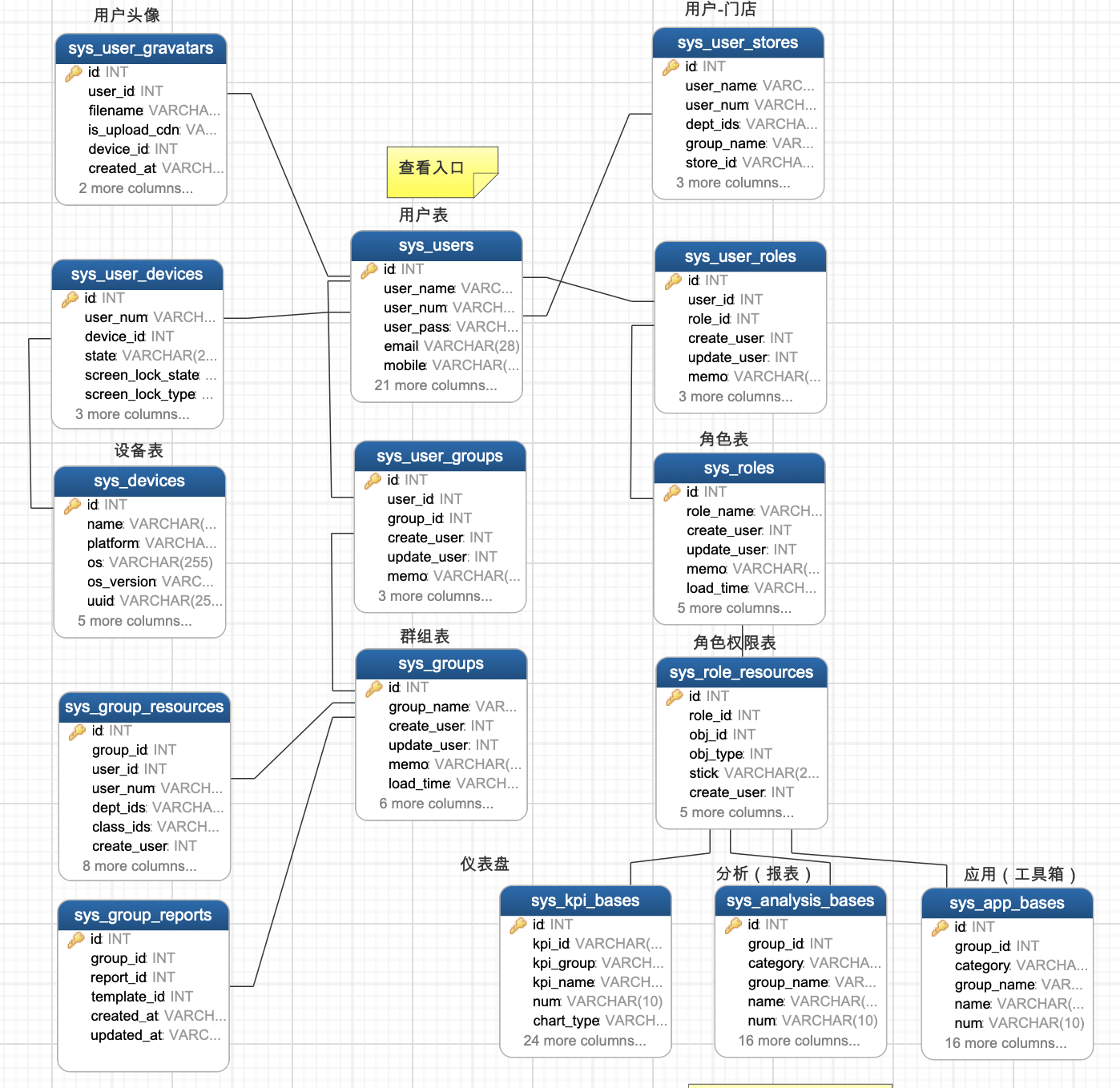
注: attachments/navicat-data-modeler-database-model/MySQL-ER图示例.ndm